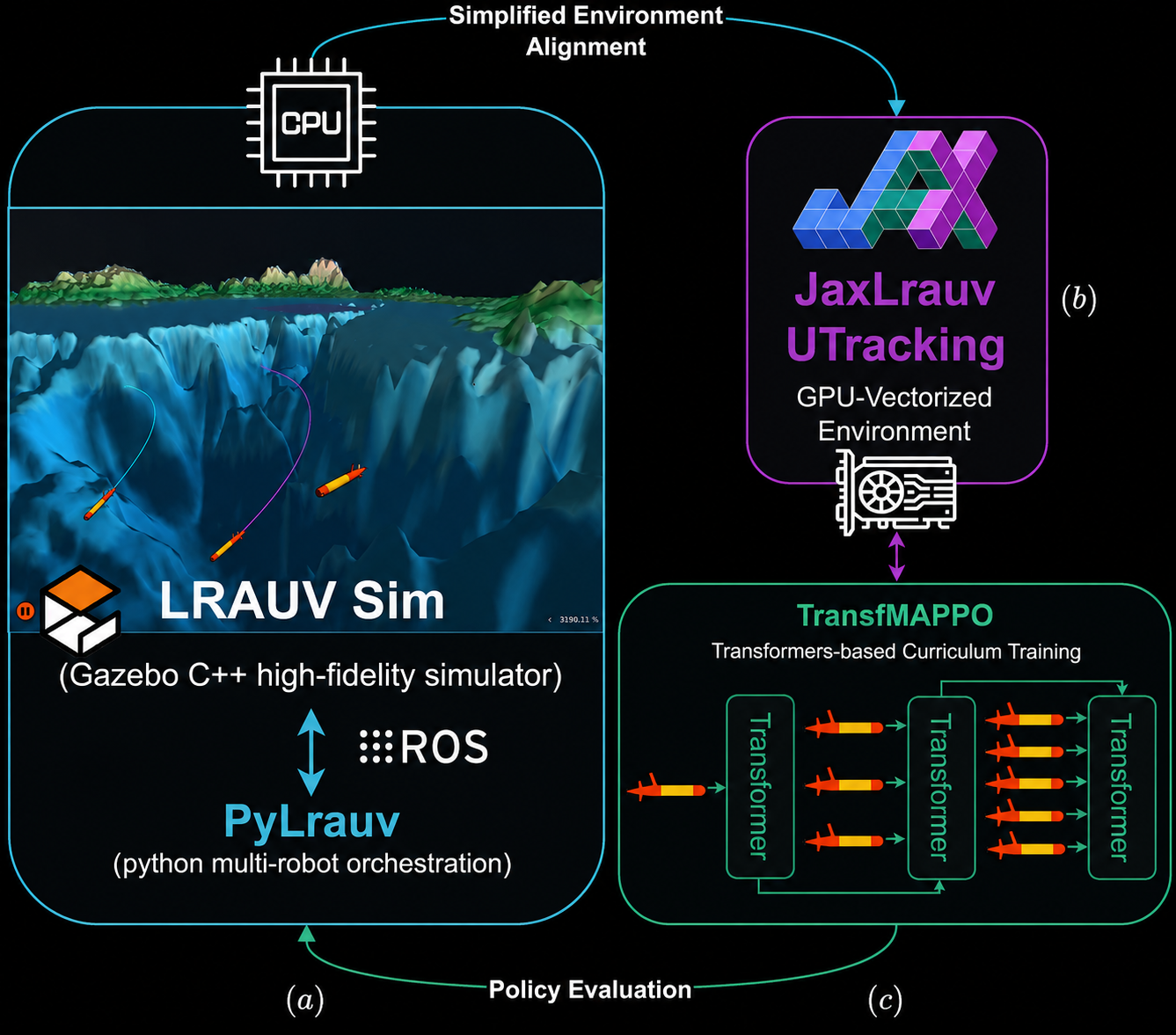
 Training pipeline: GPU-accelerated JaxLrauv for fast training, high-fidelity PyLrauv for evaluation.
Training pipeline: GPU-accelerated JaxLrauv for fast training, high-fidelity PyLrauv for evaluation.We are excited to present our ICRA 2026 paper on scaling Multi-Agent Reinforcement Learning (MARL) for cooperative underwater acoustic tracking. The core challenge: underwater missions involving AUVs controlled by MARL must be properly evaluated before deployment; high-fidelity simulators like Gazebo’s LRAUV are too slow for MARL training, yet essential for closing the sim-to-real gap. We solve this with a two-part pipeline — a GPU-accelerated JAX environment (JaxLrauv) for fast training, and a Python interface to Gazebo (PyLrauv) for high-fidelity evaluation — combined with a Transformer-based MAPPO variant (TransfMAPPO) that learns fleet-size invariant policies via curriculum learning.
TL;DR #
Training cooperative fleets of autonomous underwater vehicles (AUVs) with MARL is bottlenecked by simulation speed. Gazebo’s LRAUV simulator runs at only ~10× real-time for a single robot — making MARL training completely impractical. Our contributions:
- JaxLrauv: A GPU-accelerated JAX environment that achieves up to 30,000× speedup over Gazebo while preserving its dynamics. Train a tracking policy in 10 minutes instead of weeks.
- PyLrauv: A Python/ROS2 interface to the high-fidelity LRAUV Gazebo simulator enabling seamless evaluation and real-robot deployment.
- TransfMAPPO: A Transformer-based MAPPO that learns policies invariant to fleet size and number of targets, enabling curriculum learning across progressively harder scenarios.
- Final policies track 5 simultaneous fast-moving targets with only 5 vehicles, maintaining tracking errors below 5 m — while state-of-the-art methods require up to 12 vehicles to track 4 targets.
⚡️ speedup #
JaxLrauv provides massive speedups over the Gazebo simulator across all agent–target configurations:
| Config | PyLrauv (SPS) | JaxLrauv 1 Env | JaxLrauv 128 Envs | JaxLrauv 1024 Envs |
|---|---|---|---|---|
| 1A, 1T | 2.7 | 477× | 25,352× | 30,229× |
| 2A, 2T | 1.0 | 1,084× | 20,017× | 21,867× |
| 3A, 3T | 0.4 | 2,439× | 21,139× | 22,663× |
| 4A, 4T | 0.3 | 3,571× | 18,125× | 19,070× |
| 5A, 5T | 0.2 | 4,751× | 17,607× | 18,142× |
These gains are the difference between training taking months vs. minutes.
🌊 the pipeline #
PyLrauv #
PyLrauv wraps the official Gazebo LRAUV C++ library with a Python/ROS2 interface, exposing a Gym-like API for controlling any number of LRAUV vehicles and targets in the high-fidelity simulator. Since real LRAUV vehicles use the same ROS2 stack, the same controllers work for real-world deployment.
The UTrackingEnv manages acoustic communication (via the Gazebo Acoustic Comms Plugin), range measurements, tracking model updates, observation construction, and reward calculation. A step lasts 30 seconds of simulated time — agents listen for range signals at the start and broadcast their positions and observations at the end.
 LRAUV model in Gazebo
LRAUV model in GazeboJaxLrauv #
Gazebo models LRAUV dynamics at the millisecond level, but missions span hours. JaxLrauv focuses on what matters: the position change over a 30-second step. Given current position $\mathbf{p}_t$, speed $v$, and rudder angle $\gamma$, we predict the new position as:
$$\mathbf{p}_{t+1} = \mathbf{p}_t + v\,\delta_t \begin{bmatrix} \cos(\psi_t + \delta_\psi), & \sin(\psi_t + \delta_\psi) \end{bmatrix}$$
where $\delta_\psi = \theta(\gamma)$ is approximated by a linear model fit to Gazebo trajectories ($R^2 = 0.99$, MAE < 0.015 rad). All remaining aspects — sensor noise, communication dropout, partial observability, and collision handling — are implemented from Gazebo data.
The entire environment runs in JAX, including a vectorized Particle Filter that updates all particles across targets, agents, and parallel environments in a single GPU pass. This makes end-to-end GPU training possible.
🤖 TransfMAPPO #
Standard MAPPO with RNNs fails to generalize across different fleet sizes. TransfMAPPO addresses this by treating the multi-agent coordination problem as learning a latent coordination graph via self-attention.
Each agent (and the centralized critic) is implemented as a Transformer network. The $n$ agents and targets are represented as a set of entity vectors — each encoding relative 3D distance, velocity, and a one-hot role identifier (self / teammate / target). These vectors become the graph vertices; self-attention learns which entities to attend to and how.
This gives two key properties:
- Permutation invariance: the Transformer doesn’t care about the order of agents/targets.
- Size invariance: adding a new agent just means adding a new vertex — no architecture changes needed.
The TransformerAgent (actor) operates with local observations only, enabling decentralized execution. The TransformerCritic uses the full global state (true positions, velocities, orientations) and is used only during training (CTDE). Following our prior work, LayerNorm across the entire network is crucial for stability.
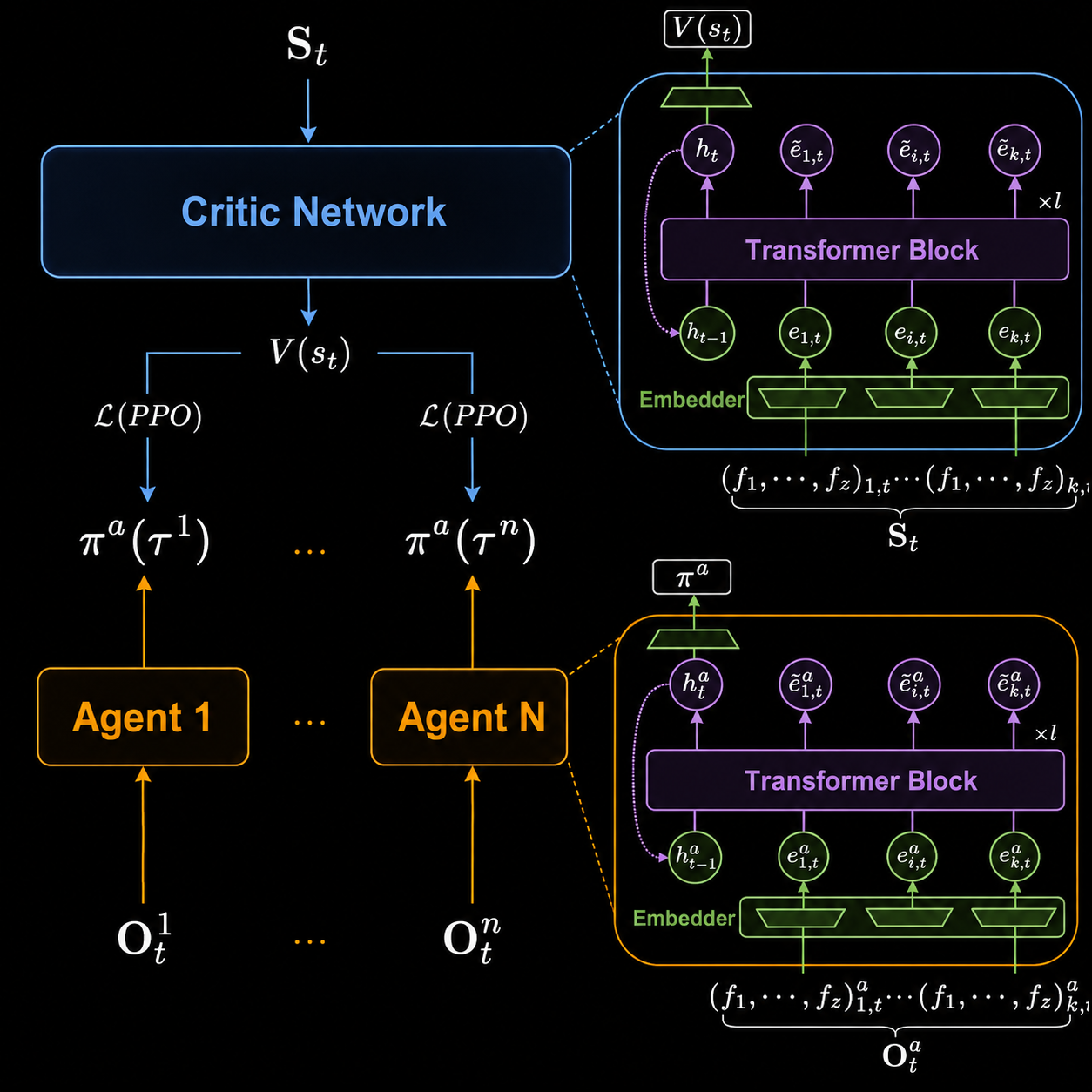 TransfMAPPO: both actors and centralized critic are Transformer networks processing entity sets.
TransfMAPPO: both actors and centralized critic are Transformer networks processing entity sets.📈 curriculum learning #
Fleet-size invariance enables a curriculum learning (CL) pipeline that progressively trains policies on increasingly hard scenarios:
Single-agent pre-training ($10^{10}$ steps, ~1.5 days on H100): Train one agent to track a fast target (0.6× its velocity) with a tracking reward. We progressively extend episode length from 128 → 256 → 512 → 1024 steps until the policy tracks for 10,000+ steps (3+ days real-time) without losing the target.
Multi-agent fine-tuning (up to $2^9$ steps): Initialize all agents from the single-agent checkpoint (identical weights, one per vehicle). Reset the critic once (new credit assignment structure). Fine-tune on two branches:
- N agents, N targets (follow reward): progressively increase to 5 agents/targets.
- N agents, 1 very fast target (tracking reward): progressively increase to 3 agents.
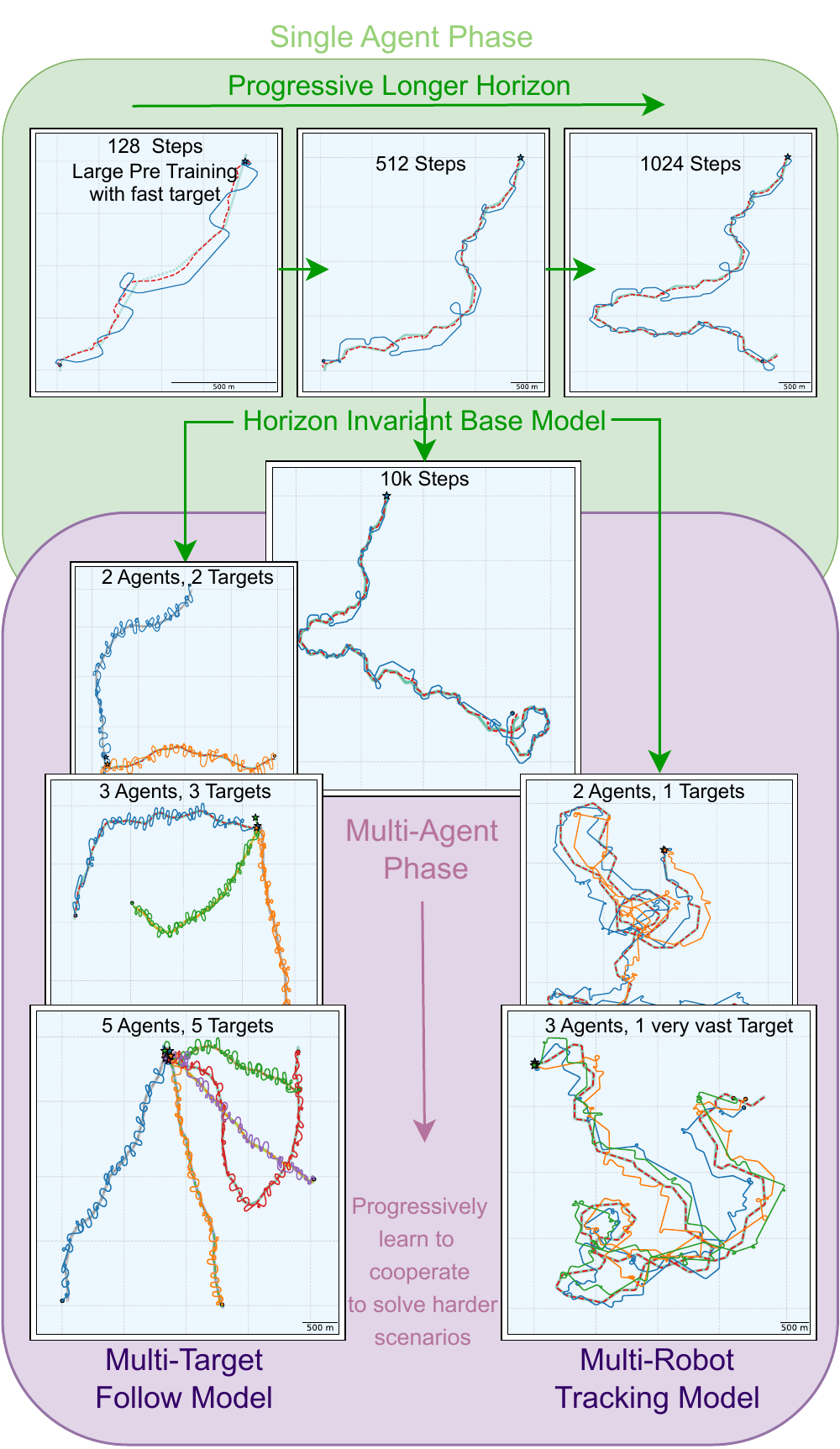 Curriculum learning: from single-agent tracking to coordinated multi-target following.
Curriculum learning: from single-agent tracking to coordinated multi-target following.The benefits of CL vs. training from scratch are stark:
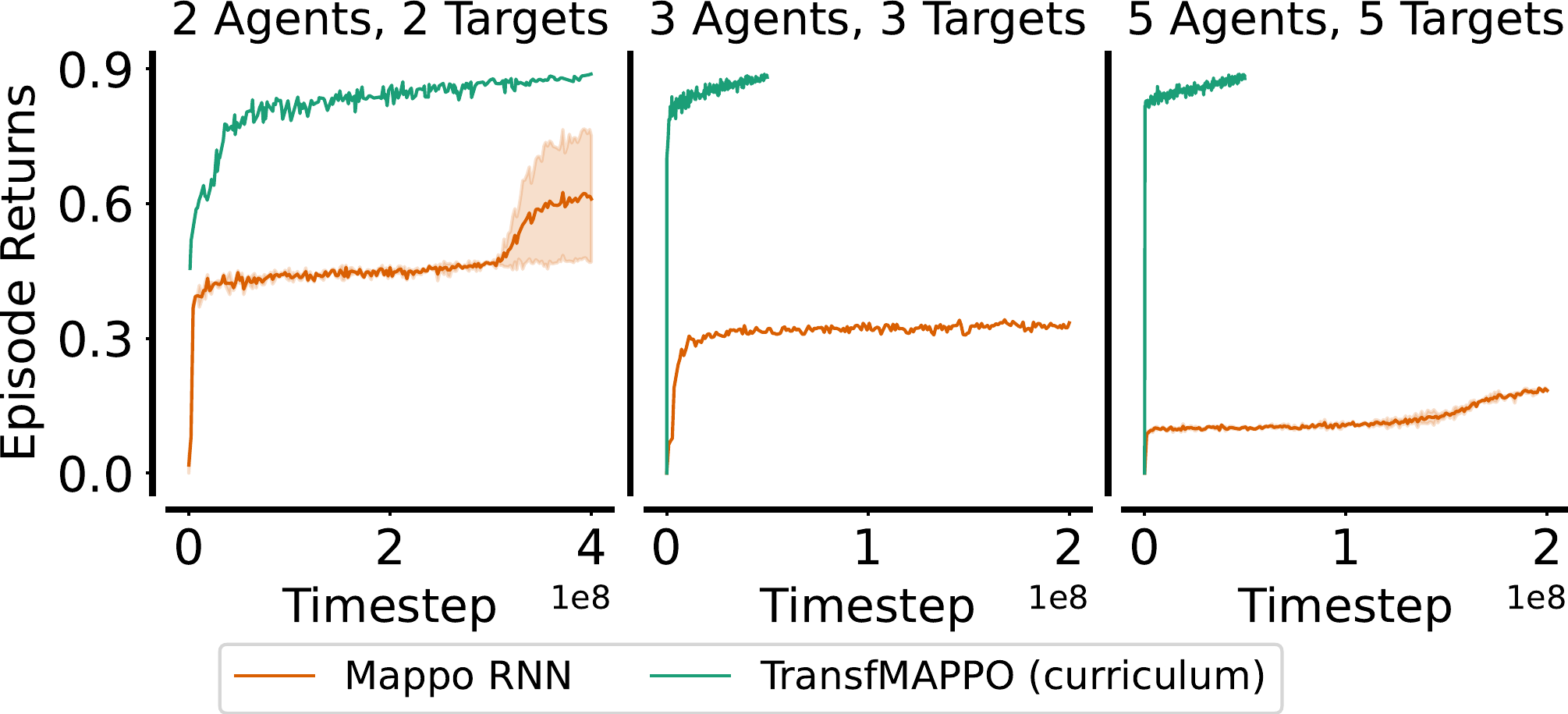 Multi-target following: MAPPO struggles, curriculum succeeds
Multi-target following: MAPPO struggles, curriculum succeeds |
🔬 results in Gazebo #
Final policies trained in JaxLrauv are evaluated directly in the high-fidelity Gazebo simulator over 50 episodes. Performance transfers remarkably well:
| Configuration | Avg. Tracking Error (JaxLrauv) | Avg. Tracking Error (Gazebo) | P(lose target) Gazebo |
|---|---|---|---|
| 1A, 1T (slow, 10min training) | 5.12 m | 5.89 m | 0% |
| 1A, 1T (fast) | 17.40 m | 20.33 m | 7.1% |
| 3A, 1T (very fast) | 2.65 m | 3.03 m | 0% |
| 3A, 3T (moderate) | 4.85 m | 5.29 m | 5% |
| 5A, 5T (moderate) | 3.80 m | 4.25 m | 5.3% |
Takeaways:
- A model trained for just 10 minutes achieves reliable single-target tracking.
- 3 agents tracking a very fast target achieves 3 m average error — far better than a single agent.
- 5 agents following 5 targets with <5% probability of losing any target.
- JaxLrauv and Gazebo results are closely matched, confirming sim-to-sim transfer.
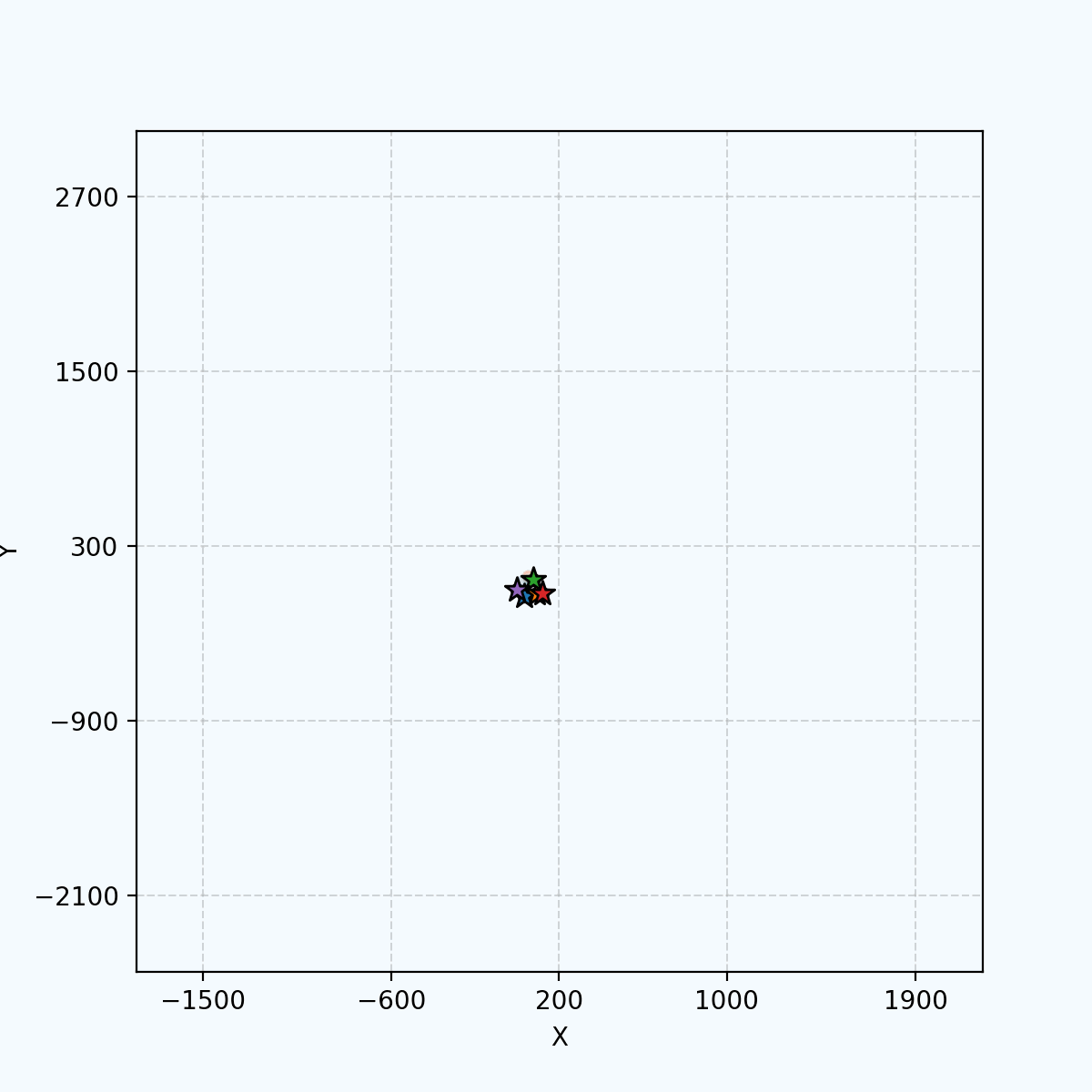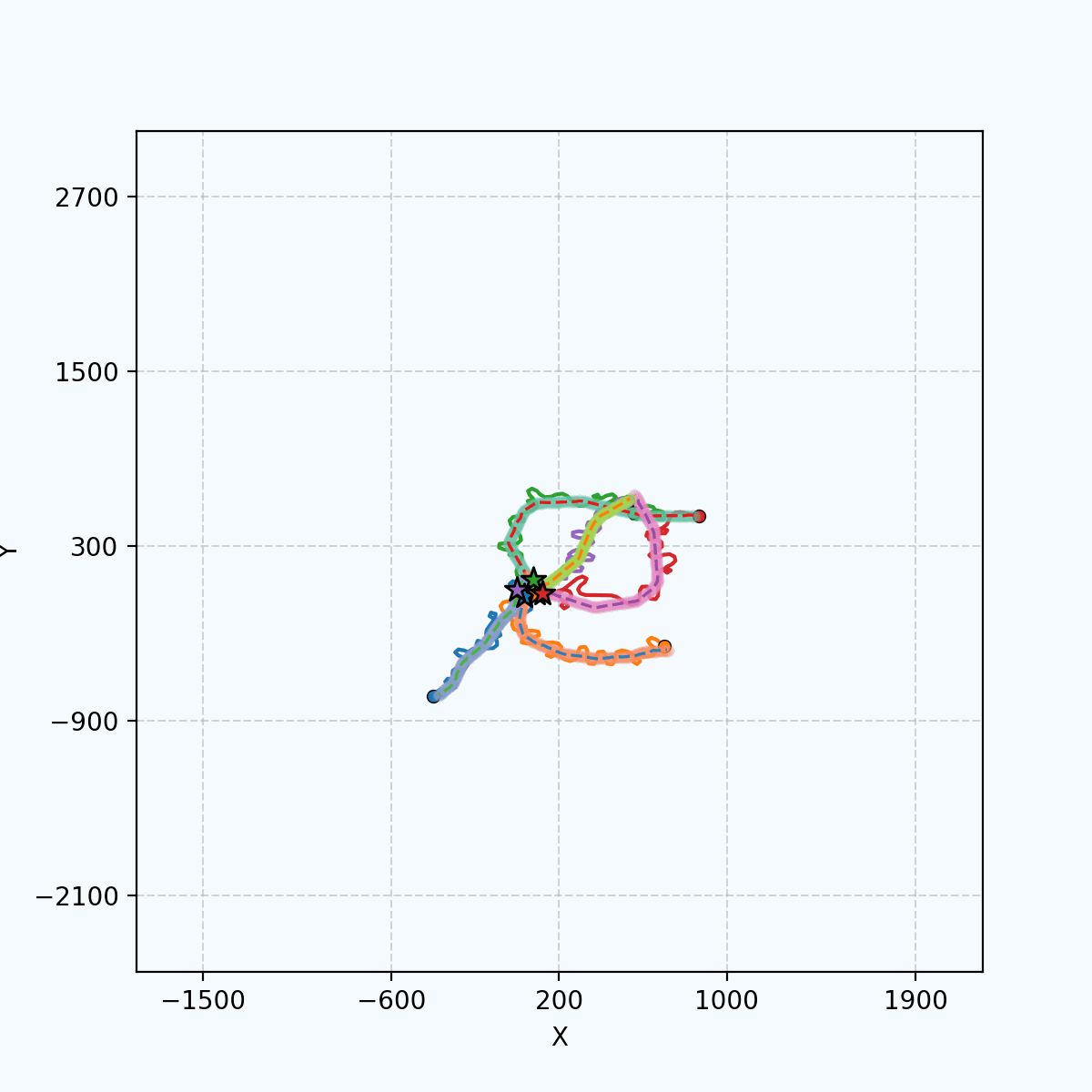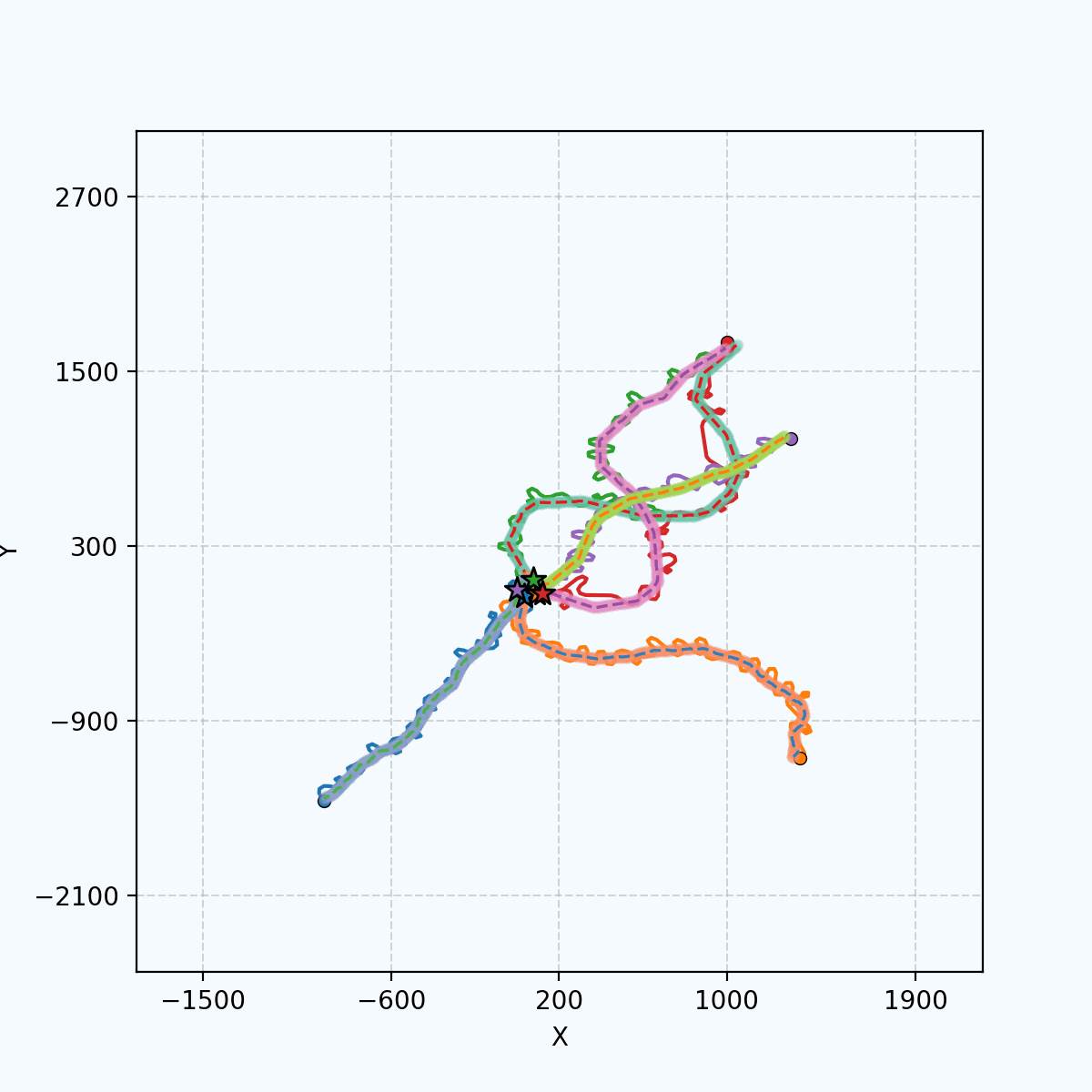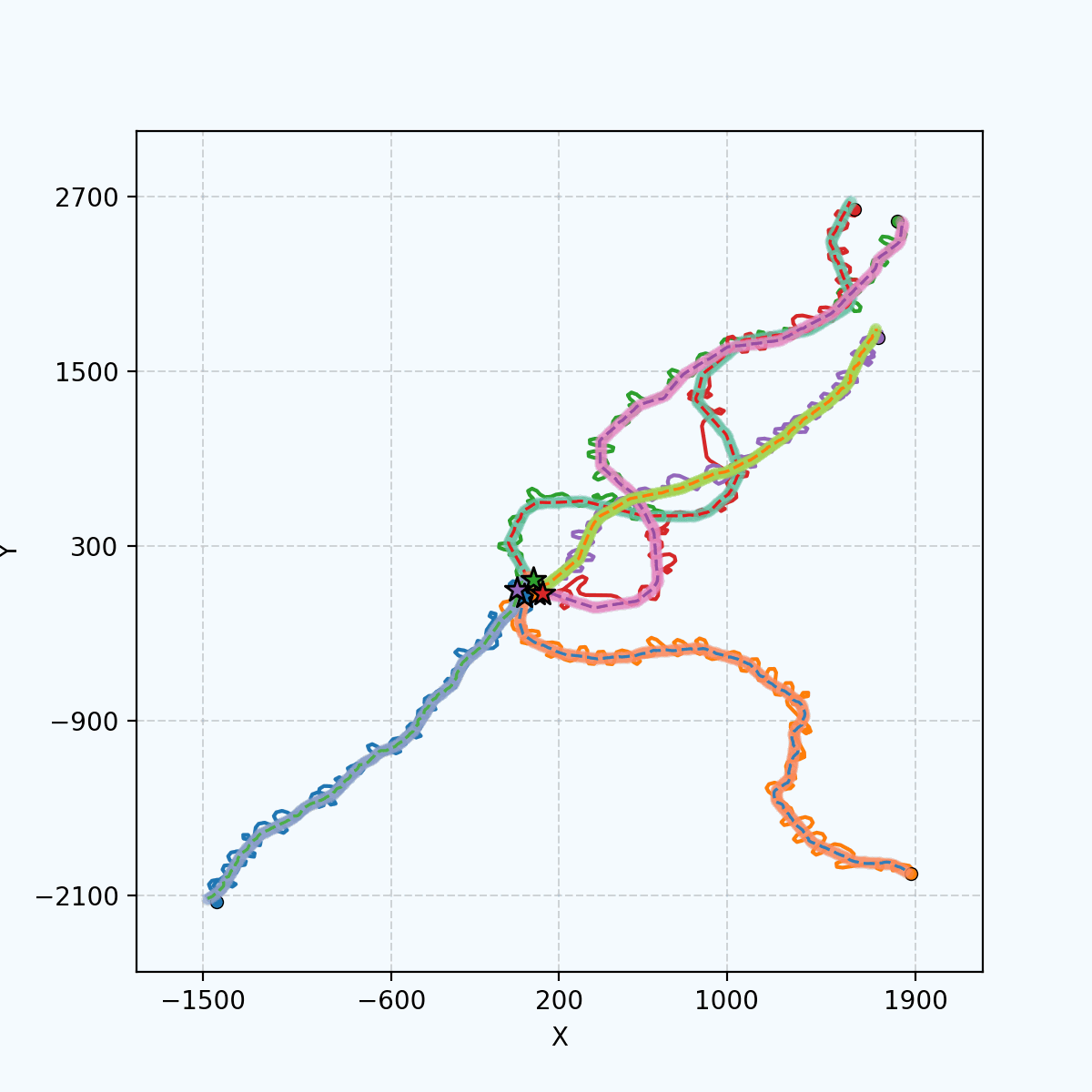 5 agents tracking 5 targets in Gazebo.
5 agents tracking 5 targets in Gazebo.emergent coordination #
The agents develop interpretable coordination strategies entirely from reward signals:
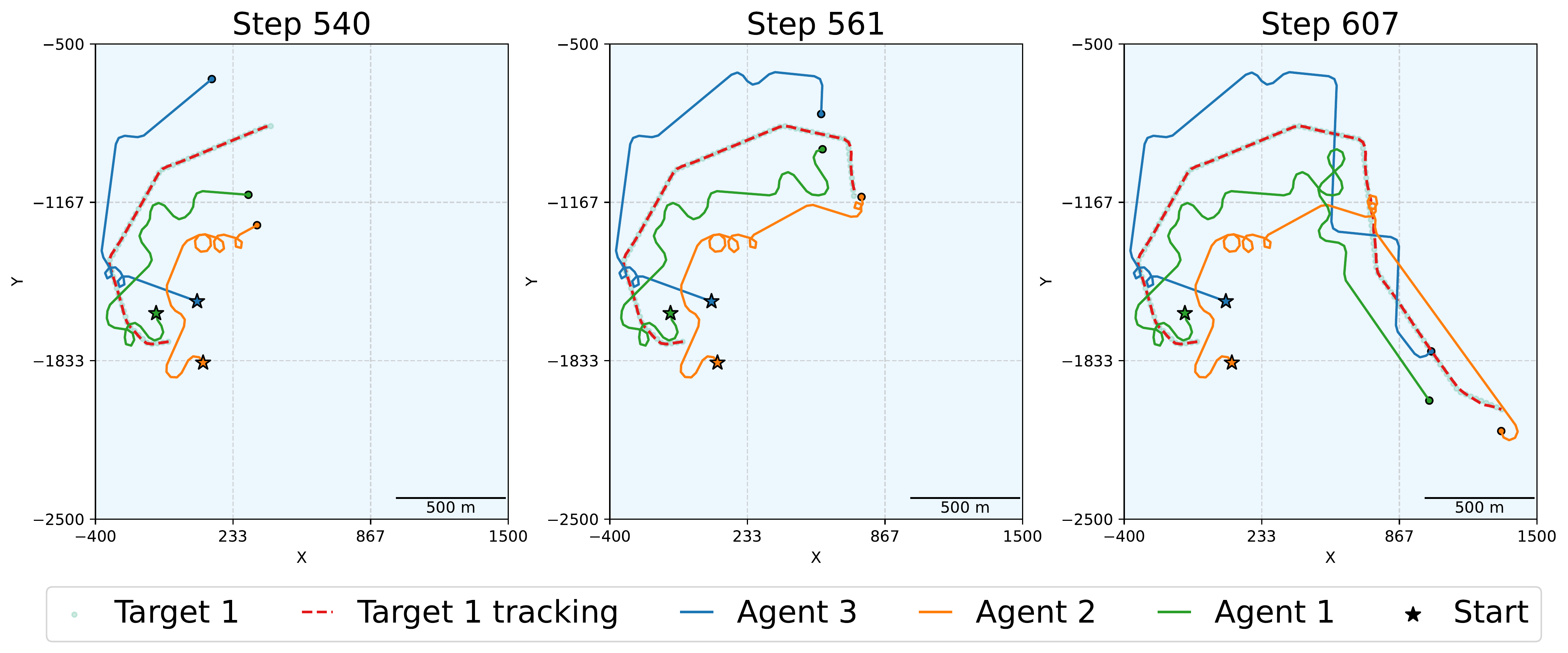 3 agents tracking a very fast target: agents wait for each other after a target direction change to preserve communication, then move together.
3 agents tracking a very fast target: agents wait for each other after a target direction change to preserve communication, then move together.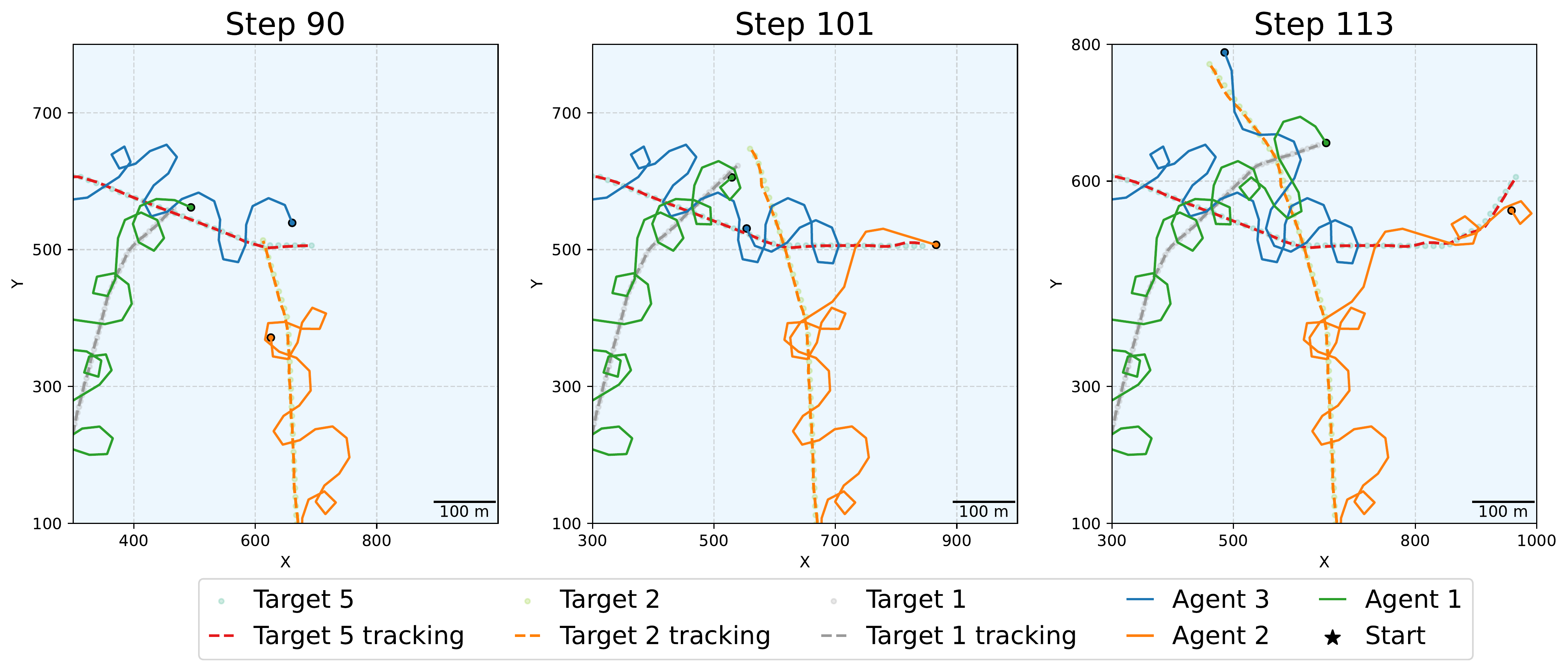 5 agents following 5 targets: agents make circles to yield right-of-way, and dynamically reassign targets when a handover is beneficial.
5 agents following 5 targets: agents make circles to yield right-of-way, and dynamically reassign targets when a handover is beneficial.evaluation #
We evaluate the final curriculum-trained policy across three robustness axes: (1) target speed — how tracking degrades as the target moves faster; (2) motion unpredictability — measured by the frequency of direction changes; and (3) agent perturbations — additional noise on agent trajectories simulating ocean currents. Each condition is swept across fleet sizes (1–5 agents), with each data point averaged over 1,000 episodes of 256 steps.
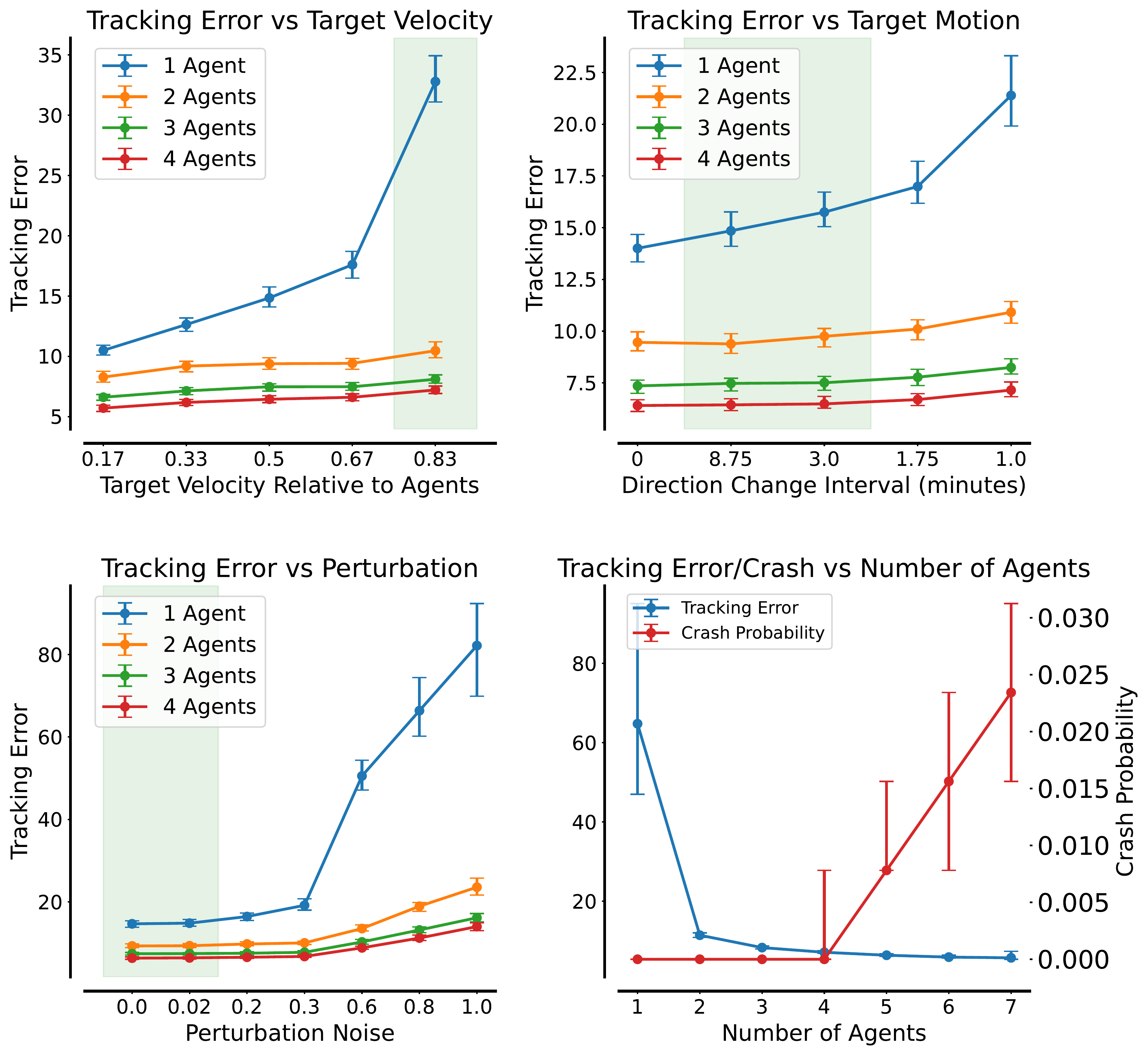 Tracking error and collision rate across target speed, motion unpredictability, and perturbation noise, for 1–5 agents.
Tracking error and collision rate across target speed, motion unpredictability, and perturbation noise, for 1–5 agents.Even two agents substantially improve robustness over a single-agent baseline. Performance scales monotonically with fleet size across all three conditions — faster targets, more erratic motion, and stronger currents all become more manageable with more agents. Three agents is a practical sweet spot: collision probability becomes negligible while tracking error approaches the multi-agent optimum, making it the most cost-effective configuration for deployment.
📦 related projects #
- JaxMARL — GPU-accelerated MARL environments in JAX
- PureJaxRL — pure JAX RL implementations
- PQN — our prior work on parallelised Q-learning
- Mava — JAX-based MARL framework
citation #
@inproceedings{Gallici2025jaxlrauv,
title={Scaling Multi-Agent Reinforcement Learning for Underwater Acoustic Tracking via Autonomous Vehicles},
author={Matteo Gallici and Ivan Masmitja and Mario Martín},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2025},
}